
摘要
短链服务作为现代互联网基础设施,通过将冗长的URL转换为简短字符串,解决了多种业务场景下的链接分发问题。本文从背景、原理到技术实现,系统梳理短链服务的设计方案。
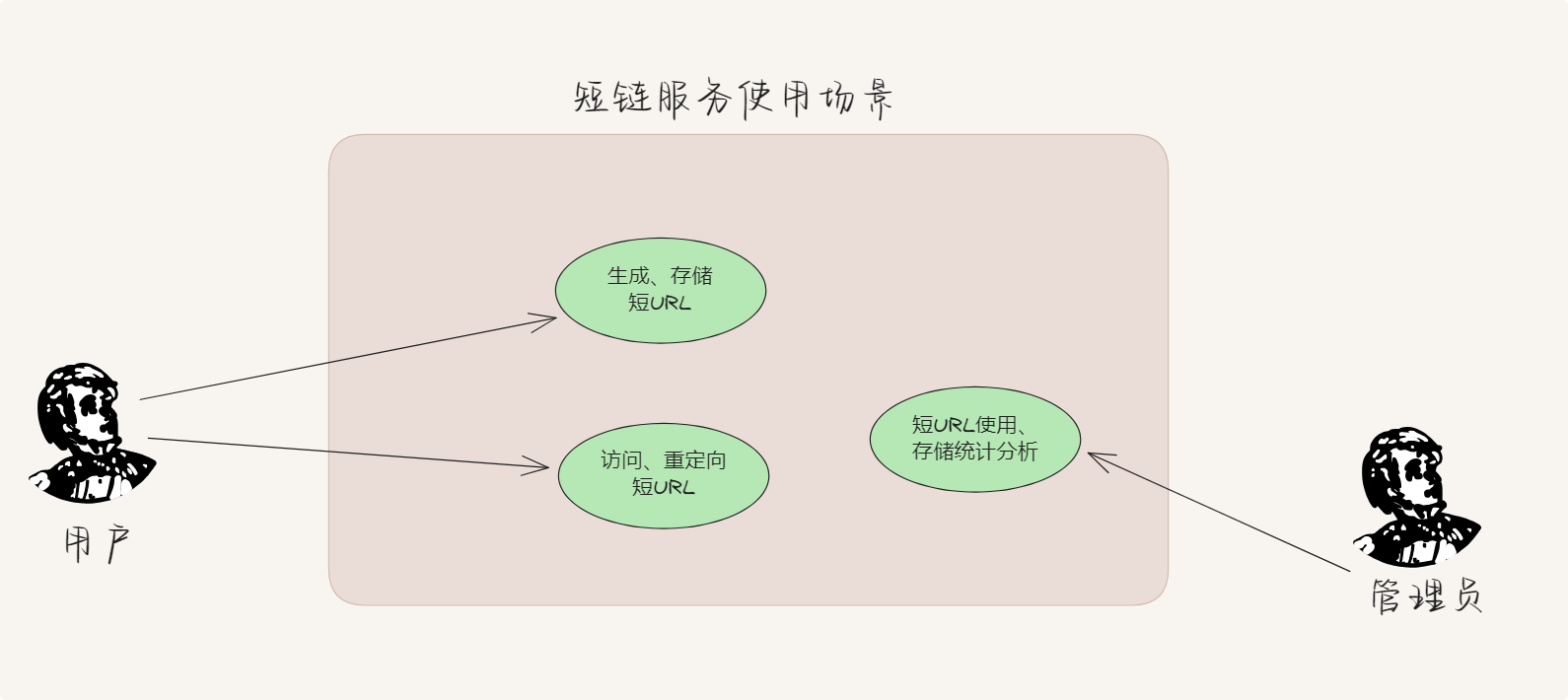
1. 短链产生的背景与意义
为什么需要短链服务?
在当今信息爆炸的互联网环境中,原始URL往往过长且复杂,带来了一系列问题:
- 易读性差:冗长的URL难以记忆,不便于口头传播
- 平台限制:社交媒体平台对URL长度有限制,过长URL可能被截断
- 参数暴露:原始URL中的参数暴露了业务逻辑和数据结构
- 缺乏统计:无法跟踪链接的点击、转化和来源等数据
- 美观性差:冗长URL在印刷品或短信中显得笨重
短链服务通过生成简短、规范的URL,优雅地解决了上述问题,同时为营销活动、用户跟踪和数据分析提供了强大支持。
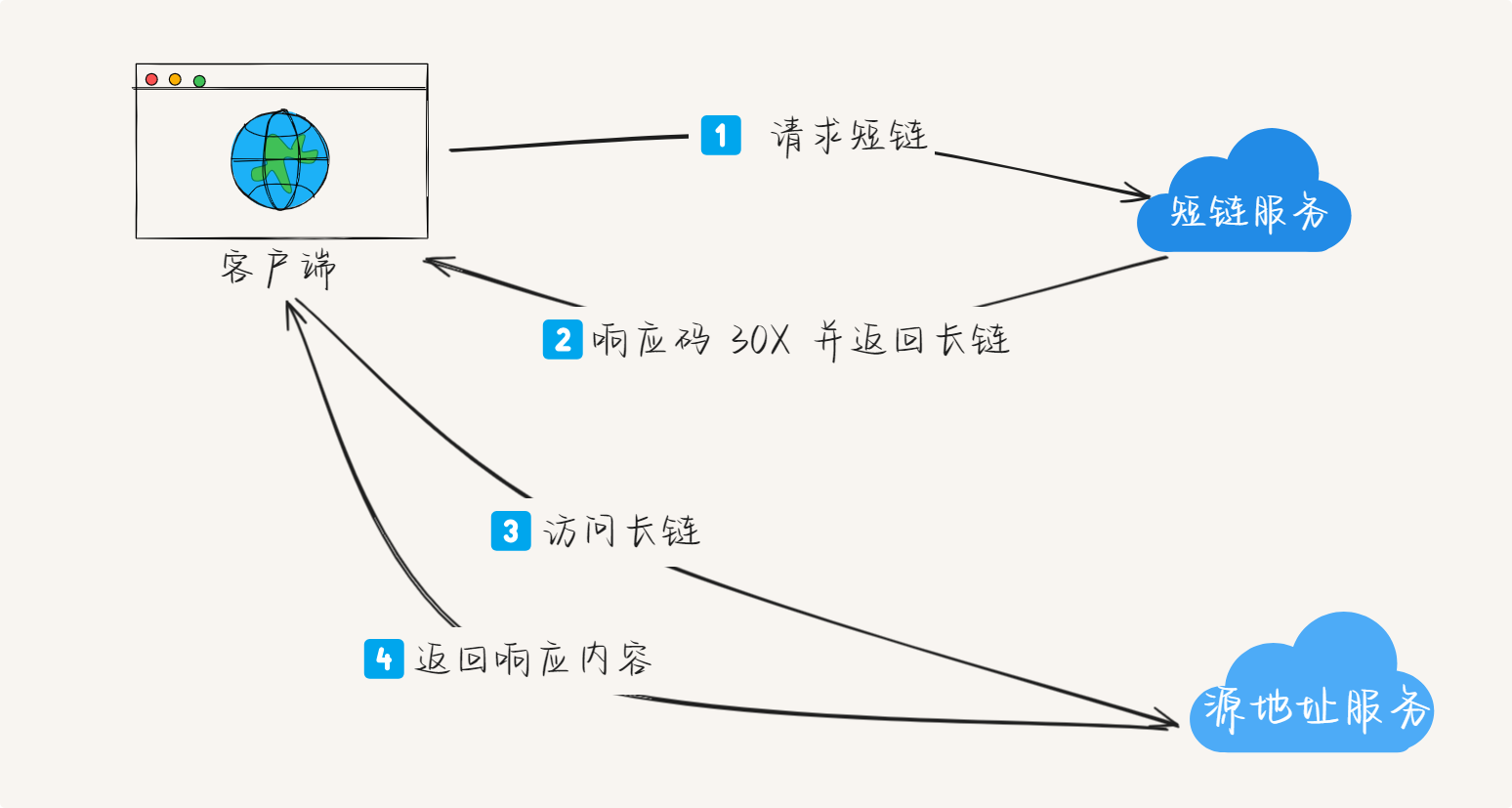
2. 短链服务工作原理
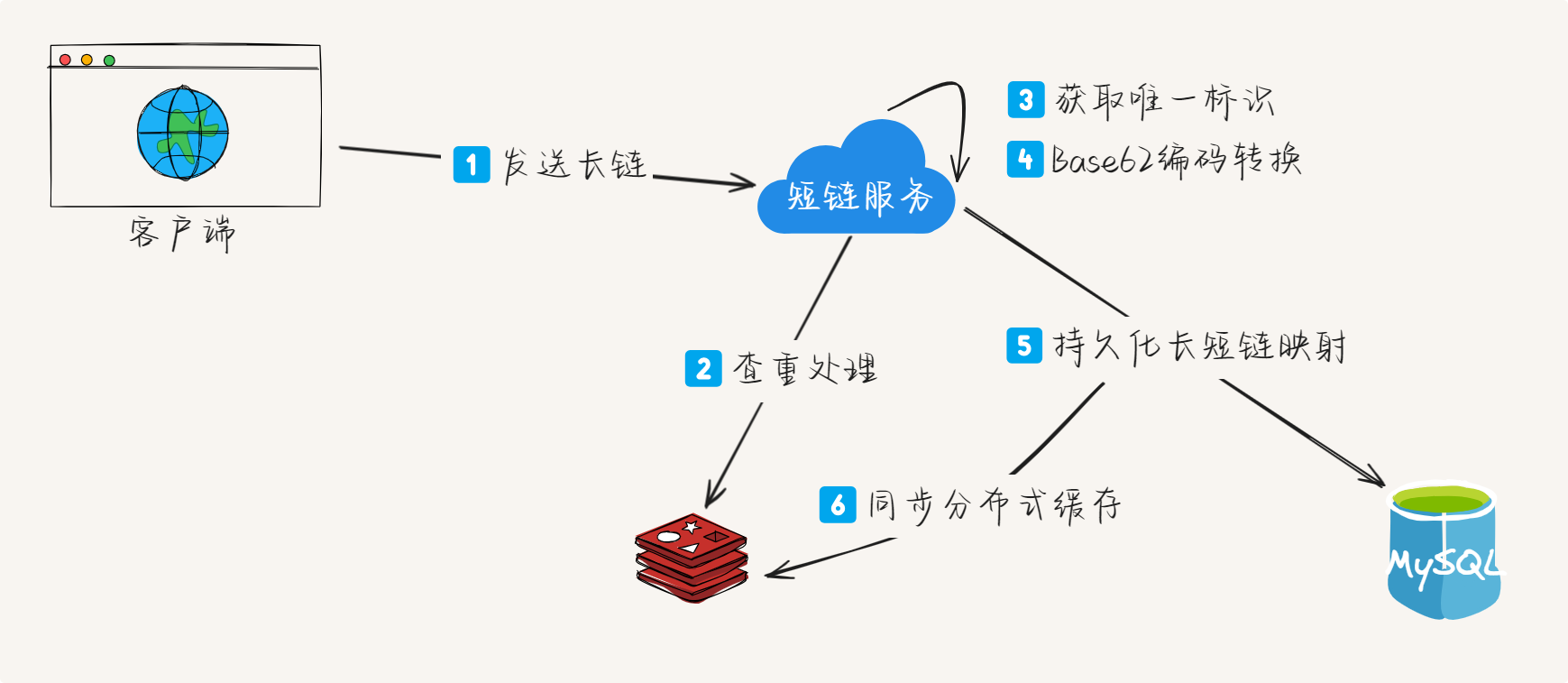
2.1 短链生成流程
生成流程
短链生成是将长URL转换为简短字符串的过程,关键步骤包括:
- 查重处理:检查长URL是否已生成过短链,避免重复
- 获取标识:通过算法或发号器获取唯一标识符
- 编码转换:将标识符通过特定算法(如Base62)编码为短字符串
- 持久化:将长短URL的映射关系存储到数据库和缓存
- 返回结果:拼接域名和路径,返回完整短链接
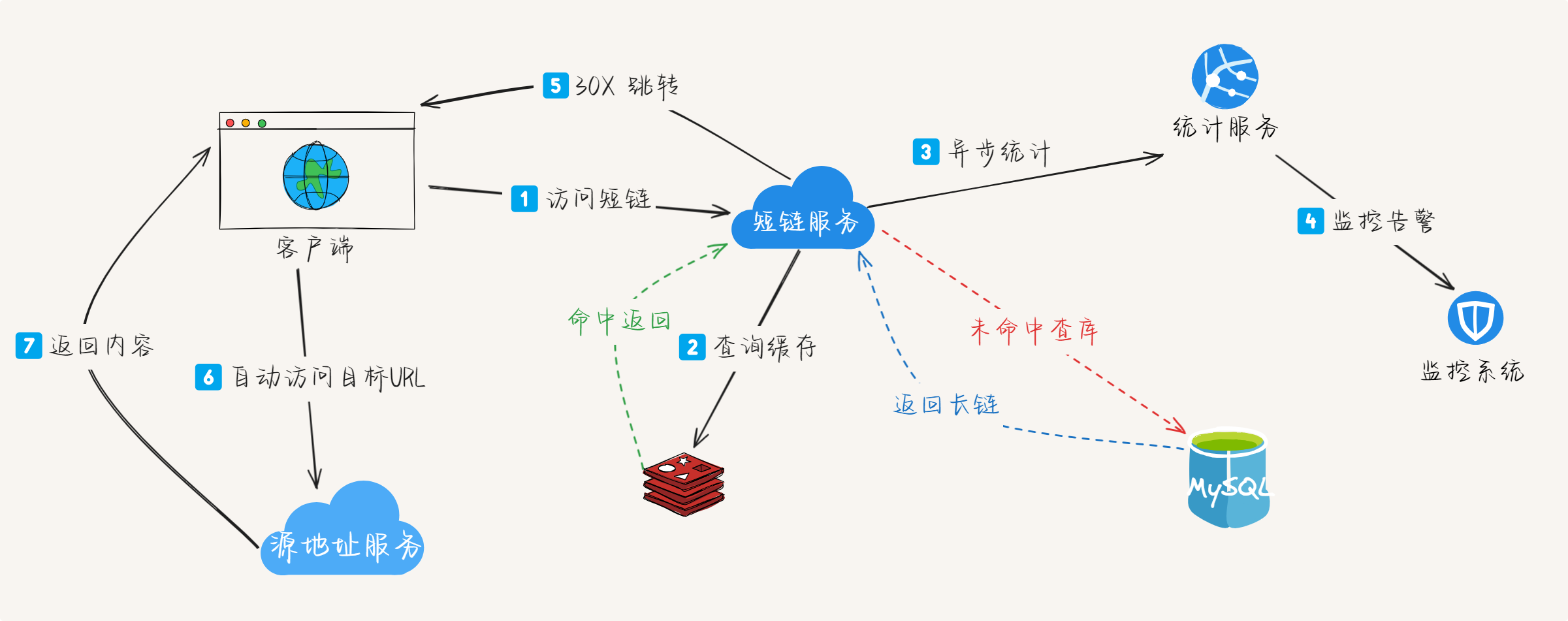
2.2 短链访问重定向流程
重定向流程
短链接访问重定向是解析短链并将用户引导到原始URL的过程:
- 解析短链:从URL中提取短链标识符
- 查询映射:优先查询缓存,未命中则查询数据库
- 统计记录:异步记录访问信息(IP、时间、设备等)
- 重定向:通过HTTP 3xx状态码将用户重定向到原始URL
- 监控报警:对失效链接或异常访问进行监控
3. 短链服务关键设计点
3.1 HTTP重定向状态码选择
301 vs 302重定向
| 状态码 | 描述 | 优势 | 劣势 | 推荐场景 |
|---|---|---|---|---|
| 301 | 永久重定向 | 浏览器会缓存,减少服务器压力 | 无法统计点击数据,更新目标URL困难 | 静态不变的永久短链 |
| 302 | 临时重定向 | 每次都会请求服务器,可统计点击量 | 增加服务器负载 | 需要统计和分析的短链 |
最佳实践:选择302重定向,为访问统计和链接管理提供更大灵活性。如果系统负载过高,可针对特定场景使用301。
3.2 短链生成算法
短链长度与容量
短链标识符长度直接决定了系统容量:
- 使用Base62编码(0-9, a-z, A-Z),每个字符可表示62种可能
- 6位短链可表示约568亿个链接 (62^6),足够满足大多数业务需求
- 权衡考虑:位数越少,易读性越好;位数越多,容量越大
3.2.1 哈希算法方案
哈希算法
原理:对长URL计算哈希值,截取一定位数转为短链标识
优点:
- 计算速度快,本地即可生成
- 同一URL总是生成相同短链
缺点:
- 存在哈希冲突风险
- 难以自定义短链
常用算法:MurmurHash(非加密哈希,性能优异)
// MurmurHash实现示例
public String generateShortUrl(String longUrl) {
long hashValue = MurmurHash3.hash32(longUrl);
return base62Encode(hashValue).substring(0, 6); // 取前6位
}3.2.2 发号器方案
全局唯一ID发号器
原理:通过集中式服务生成唯一ID,转换为短链标识
主流实现:
- MySQL自增ID
- 优点:实现简单,严格递增
- 缺点:单点故障,扩展性差
- 优化:号段模式,一次获取一批ID在内存中分配
- Redis
- 优点:高性能,可用INCR命令原子递增
- 缺点:需要持久化确保不丢失
- 应用:适合中等规模系统
- ZooKeeper
- 优点:强一致性,可靠性高
- 缺点:性能较低,适合低频生成场景
- 应用:分布式环境下的统一ID管理
// Redis实现示例
public String generateShortUrl() {
Long id = redisTemplate.opsForValue().increment("short_url_counter");
// 可选:添加随机性防止被遍历
id = addRandomBits(id);
return base62Encode(id);
}3.2.3 雪花算法及优化
雪花算法(Snowflake)
原理:组合时间戳、工作机器ID和序列号生成64位ID
优点:
- 分布式环境下无需中心化发号器
- 生成ID趋势递增,对索引友好
- 自带时间信息,便于分片和回溯
缺点:
- 依赖系统时钟,时钟回拨会导致ID重复
Seta算法(雪花算法改良版):
- 调整位序,将机器ID与时间戳位置调换
- 采用"时间超前消费"机制解决时钟回拨问题
- 位段划分更合理,应对更多业务场景
// 改良版雪花算法示意
public class SetaIdGenerator {
private final long workerId;
private long sequence = 0L;
private long lastTimestamp = -1L;
private long timeOffset = 5L; // 允许时间偏移量
public synchronized long nextId() {
long timestamp = timeGen();
// 时钟回拨处理
if (timestamp < lastTimestamp) {
if (lastTimestamp - timestamp < timeOffset) {
// 在可接受范围内,等待时钟追上
timestamp = waitNextMillis(lastTimestamp);
} else {
throw new RuntimeException("Clock moved backwards");
}
}
// 其余逻辑与标准雪花算法类似
// ...
return ((timestamp << 22) |
(workerId << 12) |
sequence);
}
// ...
}3.3 数据模型设计
数据库表设计
索引设计考量:
short_url设为唯一索引,保证短链唯一性long_url创建前缀索引,优化查重操作- 根据业务需求,可添加
user_id、expire_at等索引
CREATE TABLE `url_mapping` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`short_url` varchar(10) NOT NULL COMMENT '短链标识',
`long_url` varchar(2048) NOT NULL COMMENT '原始URL',
`user_id` varchar(64) DEFAULT NULL COMMENT '创建用户',
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`expire_at` timestamp NULL DEFAULT NULL COMMENT '过期时间',
`status` tinyint NOT NULL DEFAULT '1' COMMENT '状态:1-正常 2-已过期 3-已禁用',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_short_url` (`short_url`),
KEY `idx_long_url` (`long_url`(768)),
KEY `idx_user_id` (`user_id`),
KEY `idx_expire` (`expire_at`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='URL映射表';
CREATE TABLE `url_access_log` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`short_url` varchar(10) NOT NULL COMMENT '短链标识',
`user_agent` varchar(512) DEFAULT NULL COMMENT '用户代理',
`referer` varchar(1024) DEFAULT NULL COMMENT '来源页',
`ip` varchar(64) DEFAULT NULL COMMENT '访问IP',
`access_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '访问时间',
`country` varchar(64) DEFAULT NULL COMMENT '国家/地区',
`province` varchar(64) DEFAULT NULL COMMENT '省份',
`city` varchar(64) DEFAULT NULL COMMENT '城市',
PRIMARY KEY (`id`),
KEY `idx_short_url` (`short_url`),
KEY `idx_access_time` (`access_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='URL访问日志表';3.4 缓存架构设计
多级缓存策略
短链服务的读多写少特性,使其特别适合多级缓存架构:
- 本地缓存 (L1)
- 工具:Caffeine/Guava Cache
- 特点:响应最快,但容量有限
- 适用:热点短链(Top 1000)
- 分布式缓存 (L2)
- 工具:Redis Cluster
- 特点:容量大,集群化,支持持久化
- 适用:全量短链映射
- 缓存预热与更新
- 服务启动时预加载热门短链
- 写操作双写缓存和数据库
- 定时任务同步缓存与数据库
- 缓存淘汰策略
- 本地缓存:LRU (最近最少使用)
- Redis:设置合理TTL,热门短链设置更长TTL
- 基于访问频率动态调整TTL
// 多级缓存查询示例
public String getLongUrl(String shortUrl) {
// 1. 查询本地缓存
String longUrl = localCache.getIfPresent(shortUrl);
if (longUrl != null) {
return longUrl;
}
// 2. 查询分布式缓存
longUrl = redisTemplate.opsForValue().get(getCacheKey(shortUrl));
if (longUrl != null) {
// 回填本地缓存
localCache.put(shortUrl, longUrl);
return longUrl;
}
// 3. 查询数据库
UrlMapping mapping = urlMappingMapper.findByShortUrl(shortUrl);
if (mapping != null) {
longUrl = mapping.getLongUrl();
// 回填各级缓存
redisTemplate.opsForValue().set(getCacheKey(shortUrl), longUrl, 1, TimeUnit.DAYS);
localCache.put(shortUrl, longUrl);
return longUrl;
}
return null; // 短链不存在
}3.5 分库分表设计
海量数据分库分表策略
当数据量达到亿级别时,需要考虑分库分表:
分片键选择:
- 按短链分片:短链→长链查询高效,但长链→短链查询需要广播
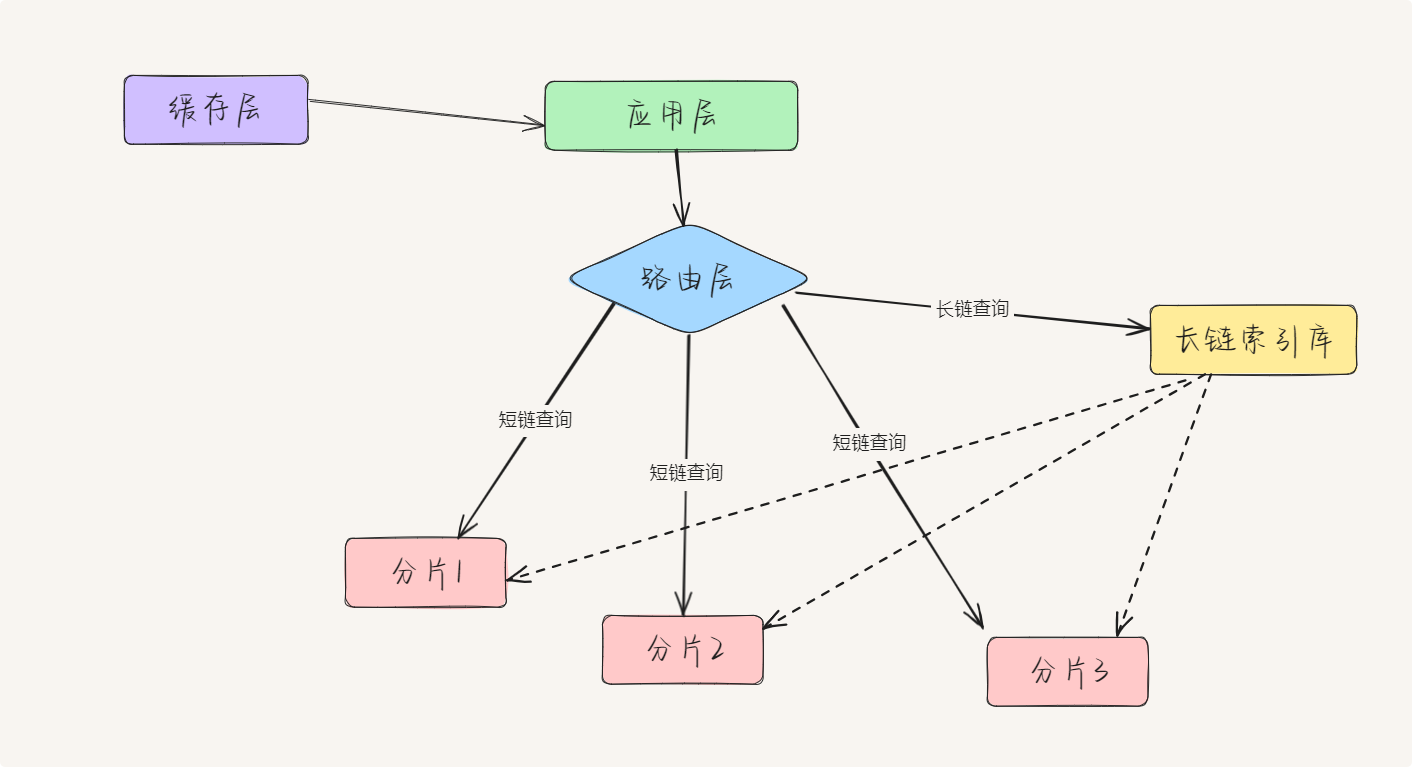
4. 实战经验与优化策略
系统可靠性保障
- 防止短链被遍历
- 在ID生成过程中混入随机因子
- 对外暴露的短链非连续
- 实施访问频率限制
- 过期链接处理
- 支持设置短链有效期
- 定时任务清理过期链接
- 过期链接跳转到指定页面
- 监控与报警
- 关键指标:生成QPS、重定向QPS、缓存命中率
- 异常监控:失效链接、异常流量、系统错误
- 容量预警:存储使用率、ID耗尽风险
4.1 性能优化最佳实践
高性能短链服务优化要点
- 异步处理
- 访问统计通过异步消息队列处理
- 非核心逻辑全部异步化
- 长链防重复
- 长链URL规范化(移除无意义参数)
- BloomFilter快速判断是否存在
- 静态资源CDN
- 短链服务页面和资源通过CDN分发
- 减轻源站压力
- 批量生成优化
- 批量获取ID,减少锁竞争
- 预取机制,号段消耗超出阈值则提前获取下一批次号段